30 Sep Ricardo Baeza-Yates: Recuperación de la Información
Entrevista a Ricardo Baeza-Yates, Catedrático ICREA en el Departamento de Tecnología de la Universitat Pompeu Fabra en Barcelona, director del Centro de Investigación de la Web del Departamento de Ciencias de la Computación de la Universidad de Chile y miembro de la Academia de Ciencias de Chile.

Ramon Bori> Tú eres un reconocido experto en recuperación de la información.
Ricardo Baeza-Yates> Supongo que sí. Sin embargo, como todo en la vida, es debido a una secuencia de casualidades. Mi tesis doctoral, que terminé en 1989, fue parte del primer gran proyecto digital en documentación, que era la informatización del diccionario inglés de Oxford. El diccionario ocupaba 540 Mb, algo que no cabía en un CD de esos tiempos. En esa época era algo gigantesco, ahora no es nada. Este proyecto comenzó a mediados de los 80, en Canadá, después que la Universidad. de Waterloo ganara un concurso internacional entre las universidades de habla inglesa.
Ramon Bori> ¿Cómo empezaste a interesarte por el tema?
Ricardo Baeza-Yates> Este tema siempre me ha interesado. Siempre he estado muy cercano a las bibliotecas, por razones familiares. Ahí comencé a interesarme por los temas de gestión de la información, después trabajé mucho en algoritmos de búsqueda, de ahí pasé a la recuperación de la información (IR: information retrieval) y por ende a los buscadores de la Web, que fue la siguiente explosión allá por 1994. Últimamente he estado interesado en la minería Web, es decir en buscar las preguntas que uno recién descubre cuándo reconoce las respuestas, cuando se encuentran regularidades en los datos.
Ramon Bori> Precisamente, eres coautor con Berthier Ribeiro-Neto de Modern Information Retrieval (Addison-Wesley, 1999), obra de referencia.
Ricardo Baeza-Yates> Es un libro de texto en el área de recuperación de la información que en su época, 1999, fue bastante innovador, porque incluye incluso a Google, que había salido justo hacía un año y en ese momento no se sabía que éxito había de tener. Ahí está, el algoritmo de pagerank que es la base inicial de Google.
Actualmente es el libro más usado en el mundo. Estamos preparando una segunda edición porque si no quedaría obsoleto. Hemos hecho algún análisis en la Web, y por lo menos se usa en trescientas universidades en el mundo para asignaturas que tratan sobre la recuperación de la información. Ha sido también traducido al chino y al coreano.

Edición Coreana, 2001
Ramon Bori> La IR, ¿es ya una asignatura obligatoria?
Ricardo Baeza-Yates> Lamentablemente aquí todavía no es, en general, un curso obligatorio. En otras países sí lo es.
Con la Web queda claro que todas estas técnicas son cada vez más importantes, al igual como lo es hoy una asignatura de base de datos.
Ramon Bori> Pero sus orígenes se remontan a la década de los sesenta
Ricardo Baeza-Yates> El padre de la recuperación de la información es Gerard Salton. En los años sesenta empezaron a trabajar con todo lo que tiene que ver con bibliotecas y otras bases de datos textuales. El tema fue decayendo porque estaba acotado, parecía que ya se había resuelto muy bien.
Ramon Bori> Y llegó la Web.
Ricardo Baeza-Yates> La Web fue un renacer de todo esto, agregando nuevas cosas por supuesto. Ha cambiado todo mucho en los últimos diez años.
Ramon Bori> ¿Explícanos cómo funciona esto de la minería Web?
Ricardo Baeza-Yates> Digamos que en la Web hay tres tipos de datos. En primer lugar, la estructura de la Web, los enlaces. Todo lo que tiene que ver con el ranking de páginas usando enlaces [por ejemplo pagerank], como en Google y otros buscadores grandes como Yahoo o MSN Search. En segundo lugar, todo lo relacionado con el contenido, es decir minería del contenido, páginas similares, temáticas, etc. Y por último, lo más interesante, lo qué hace la gente en la Web, que se llama minería de uso. Además, todos estos datos son dinámicos, pues la Web cambia permanentemente.
Estamos hablando de relacionar un poco todas esas cosas. Si una persona pregunta algo, qué es lo que hace después, qué páginas escoge. A partir de lo que la gente hace, uno puede deducir otras cosas: mejorar los buscadores, encontrar páginas parecidas, encontrar preguntas parecidas –lo que es mucho más interesante aunque las preguntas tengan palabras distintas.
En eso estamos trabajando. Los casos dominantes permiten encontrar similitudes semánticas basados sólo en los casos más comunes. Por ejemplo, si una persona cuando pregunta hipoteca va a la página de un banco y otra persona cuando pregunta préstamo va a la misma página, podemos deducir que ambas preguntas están relacionadas. Básicamente es el triunfo de la estadística sobre casos individuales.
Ramon Bori>Otro tema que has trabajado con tu grupo ha sido el mapa Web chileno.
Ricardo Baeza-Yates> Sí, hemos estudiado la evolución de la Web Chilena desde el año 2000 y creo que es el único estudio sistemático de este tipo. En la figura adjunta se muestra la estructura de la Web Chilena: MAIN es el núcleo conexo de la Web. IN sólo tiene enlaces a MAIN y OUT sólo recibe enlaces de MAIN. ISLANDS son sitios desconectados del resto, son islas. También muchos sitios desaparecen cada año. Recientemente terminamos el primer estudio a gran escala de la Web de España, un informe completísimo que tiene 60 páginas.
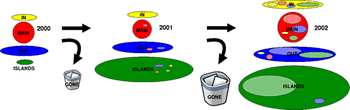
Ramon Bori> Cada vez hay más islas
Ricardo Baeza-Yates> Así es, y no sólo en Chile. Mirando desde la Web de España, más del 80% de los sitios son islas. Conocer las islas es difícil. En Chile conocemos todas las islas porque tenemos acceso a todos los nombres del dominio.cl, cosa que en España legalmente no es posible.
Hemos visto cómo evoluciona la Web, cómo los sitios van cambiando, y se necesita intuición y sentido común para entenderlo.
Ramon Bori> Háblanos de Raditech, la spin-off que comercializa la tecnología de búsqueda desarrollada por tu grupo de trabajo.
Ricardo Baeza-Yates> Ésta es una empresa que vende tecnología de búsqueda, que fue desarrollada en Brasil y Chile, y esperamos que en el futuro en Barcelona. Es la investigación que hemos hecho en los últimos quince años. Creo que tenemos tecnología competitiva con la de Google, aunque hecha en Latinoamérica, y por ello es más difícil que la gente crea que es buena. Actualmente la usa La Caixa y el BBVA en sus sitios Web, entre otros clientes.
Ramon Bori> ¿Cómo funciona? ¿explícanoslo un poco?
Ricardo Baeza-Yates> Bueno, permanentemente estamos recorriendo el sitio Web de La Caixa y actualizando el índice. Cada vez que alguien hace una pregunta, buscamos en este índice para buscar una respuesta relevante muy rápida.
Básicamente es la misma idea que usa Google, la única diferencia es que esto está hecho para un solo sitio Web no para toda la WWW. Es un buscador especializado y personalizado. Hay buscadores Web que usan nuestra tecnología como el buscador del proveedor de Internet más grande de Brasil, UOL.
Ramon Bori> ¿Cuál es el criterio de clasificación de los resultados de la búsqueda?
Ricardo Baeza-Yates> El criterio de clasificación se basa en una mezcla de enlaces con contenido y con uso. Es la alianza de distintas fuentes de información para saber cuál es la mejor página.
Lo más difícil es ordenar con una pregunta de una sola palabra, y sobre todo con una palabra que tenga más de un significado, por ejemplo «papa».
Ramon Bori>Ahora, ¿En qué estás trabajando en la Universitat Pompeu Fabra
Ricardo Baeza-Yates> Estamos haciendo un grupo en investigación en recuperación y minería en la Web. Esto incluye recuperación multimedia, minería de consultas, y minería en la dinámica de la Web, entre otros temas.
Por ejemplo, procesar las bitácoras de preguntas de un buscador y en base a esto mejorarlo o generar recursos semánticos, pseudo-diccionarios de preguntas que la gente hace pero con el lenguaje de la calle.
Ramon Bori> Todo automático
Ricardo Baeza-Yates> Sí, todo automático. Tiene que ser automático. Si no, no es escalable en el tamaño y dinamismo de la Web.
Ramon Bori> Yahoo, por ejemplo, creo que hasta hace muy poco tenía aún algunos de estos procesos no automatizados.
Ricardo Baeza-Yates> Sí, pero éste es -más bien era- el cuello de botella de Yahoo, es más caro y más lento. Para el volumen de la Web tiene que ser automático.
Nosotros desarrollamos herramientas que automáticamente van analizando todos estos datos. Tenemos que seguir trabajando porque uno está buscando lo que uno cree que puede encontrar, pero muchas veces lo que encuentra son cosas distintas. La Web tiene muchas sorpresas. Por ejemplo, modelar el usuario, cómo trabaja el usuario de un buscador, qué es lo que hace. Nosotros podemos modelar eso porque entendemos muy bien lo que hace.
Ramon Bori> ¿Tal cómo hace Amazon?
Ricardo Baeza-Yates> Sí, es lo que se llama recomendación cooperativa o colaborativa, en base a lo que han hecho otros.
Yo me estaba refiriendo a modelar un usuario en sí, qué es lo que va a hacer un usuario promedio. Por ejemplo, nosotros estamos trabajando en el sentido de que si alguien hace una pregunta tan simple como Ronaldinho, recomendarle preguntas mejores, pero preguntas que ha hecho otra persona experta en el tema. No inventarse una pregunta.
Al usuario que pregunte Ronaldinho, le puedo contestar: «pregunte por el Barça», porque sé que hay una relación y esa relación la conseguimos de una forma automática, no por medio de una enciclopedia deportiva, por ejemplo.
Ramon Bori> ¿Cómo Ask Jeeves?
Ricardo Baeza-Yates> Lo que pasa es que Ask Jeeves busca en las preguntas. O sea, tiene un conjunto de preguntas y lo primero que hace es buscar cuál es la pregunta más parecida a tu pregunta. Pero el problema de esas preguntas es que tienen una intervención manual, y eso hace que sea difícil su escalabilidad. Nuestra idea es hacer las recomendaciones de forma automática, y en base a lo que la gente hace después que pregunta.
Si alguien dice «quiero ir de veraneo», le recomiendo sitios que tiene que mirar, que no sólo tienen que ver con palabras parecidas, sino con palabras relacionadas con ?ir de vacaciones?. Todo lo podemos hacer automático, por ejemplo, si seleccionamos aquí en España, le diríamos: busque algo en Marbella o en la Costa Brava.
Ramon Bori>Otro tema de tu interés trata sobre la ubicuidad de los buscadores
Ricardo Baeza-Yates> Así es. Esto tiene que ver con el impacto de los buscadores en el resto de la Web. Los buscadores tienen muchas facetas, si el buscador no encuentra un sitio (por ejemplo porque es una isla), la gente no lo encuentra pues es probable que no esté en el buscador. Pero esto no es suficiente, porque el buscador puede encontrar el sitio, pero no puede entrar, pues no encuentra los enlaces internos. Por ejemplo, alrededor de un 20% de la Web de España no es recorrida por los buscadores pues son sitios en binario (Javascript, Flash, etc.). Ahora, si el sitio está bien hecho, el buscador entra y lo indexa.
También puede ser que la gente no encuentre lo que busca si el sitio no tiene las palabras correctas, es decir las que la gente usa. Entonces la pregunta es ¿cuáles son las palabras correctas?. Eso tiene que ver con lo que se llama esencia de la información, idea que inventó Pirolli en 1997. La idea es que para todas las palabras que tienen el mismo significado, hay palabras que son mejores que otras. Por ejemplo, para un Banco, ¿qué es mejor: crédito, préstamo o hipoteca?. Depende del contexto, de la cultura, del lenguaje. Nosotros hemos hecho herramientas para tratar de detectar, según las preguntas en el buscador de un sitio, cuáles son esas palabras que son buenas y cuales palabras faltan en el sitio.
Entonces, después que obtienes las palabras correctas, lo siguiente es que quedes entre los primeros veinte resultados, pues la gente en promedio no mira más de dos páginas de respuestas. Estas ideas están plasmadas en una de mis columnas mensuales en la revista chilena Informática, del año 2002: Cinco Claves para la Web.
Otro impacto, algo sobre lo que no he explicado nada, es que los buscadores son utilizados como herramientas para generar contenidos. Mucha gente dice: voy a escribir sobre tal tema. ¿Qué hace? Busca, pega pedazos de distintas páginas y publica el resultado. Pero esto que publicó, es en base a lo que el buscador cree que es bueno, que no necesariamente es lo mejor que existe. Mucha gente hace un acto de fe para creer que ha encontrado la mejor respuesta posible. Así que el contenido está siendo sesgado por los buscadores.
Ramon Bori> O sea, en buena medida el «preferential attachment» de Barabási lo deciden los buscadores
Ricardo Baeza-Yates> A mí me gustaría que los resultados fueran más justos. Los sitios nuevos no van a aparecer ahí. Tienen muy pocos enlaces, tienen poco pagerank. Es un poco como la televisión, donde los nuevos programas se basan en los programas más populares, que no necesariamente son los mejores. Es como una secuencia de reality shows que se van realimentando a sí mismos. En la Web, los mejores sitios que generan información van generando otros sitios. Es un poco lo que dice Linked [de Barabási] sobre los enlaces a un sitio: «los ricos se hacen más ricos y los pobres se hace más pobres», lo que también ocurre en la vida cotidiana; no hay nada realmente nuevo.
Y en la Web ocurre así porque los modelos de negocios son para pocos, es decir, los dominantes son pocos. En la Web el sesgo es mucho más estricto, pues estamos sumando el sesgo económico no sólo con el educativo, sino también con el cultural y el tecnológico. Pero al final la Web es un reflejo de nuestra sociedad. Por ejemplo, en el estudio de la Web de España mostramos que las importaciones de España tienen una alta correlación con los enlaces de la Web de España a esos mismos países.
Sorry, the comment form is closed at this time.